
Doğal dil işleme (NLP), bilgi çıkarımı ve metin madenciliği gibi alanlarda metin verilerini anlamak, analiz etmek ve bu verilerden bilgi çıkarmak önemlidir. Bu süreçlerde, metin içerisindeki kelimelerin anlamını ve önemini belirlemek için çeşitli teknikler kullanılmaktadır. Bu tekniklerden biri de TF-IDF (Term Frequency – Inverse Document Frequency) analizidir. TF-IDF, kelimelerin bir dokümandaki önemini ölçmek için kullanılan bir istatistiksel yöntemdir ve bilhassa büyük metin veri kümelerinde anlamlı kelime öbeklerini ortaya çıkarmak için sıklıkla tercih edilir.
TF-IDF (Term Frequency – Inverse Document Frequency) Analizi Nedir?
TF-IDF Nedir?
TF-IDF, bir dokümandaki kelimelerin ne kadar önemli olduğunu belirlemek için kullanılan iki ana bileşenden oluşur: Term Frequency (TF) ve Inverse Document Frequency (IDF). Bu iki bileşen, kelimenin doküman içerisindeki sıklığına ve aynı zamanda kelimenin genel doküman kümesindeki yaygınlığına bağlı olarak kelimeye bir ağırlık değeri atar.
Term Frequency (TF):
TF, bir kelimenin belirli bir dokümanda kaç kez geçtiğini ifade eder. Bu, basitçe kelimenin o dokümandaki frekansını ölçer. Ancak, dokümanlar farklı uzunluklara sahip olabileceğinden, kelimenin frekansı dokümanın toplam kelime sayısına bölünerek normalize edilir. Formülü şu şekildedir:
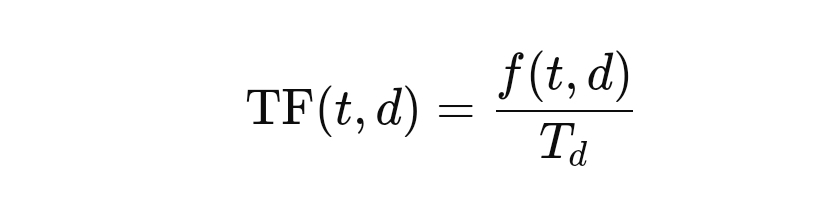
Burada, ( f(t,d) ) kelimenin (( t )) dokümanda (( d )) geçme sayısını, ( T_d ) ise dokümandaki toplam kelime sayısını ifade eder. Bu şekilde, kelimenin sık geçtiği kısa dokümanlar ile uzun dokümanlar arasındaki farklılık dengelenir.
Inverse Document Frequency (IDF):
IDF, bir kelimenin doküman kümesindeki yaygınlığını ölçer. Çok yaygın kelimeler (örneğin “ve”, “bir”, “bu” gibi) genellikle analizde önemsiz olarak kabul edilir, çünkü bu kelimeler her dokümanda yer alabilir ve içerik açısından bir ayırt edici özellik taşımazlar. IDF, yaygın kelimelerin ağırlığını azaltarak nadir kelimelerin önemini artırmayı amaçlar. IDF formülü şu şekildedir:
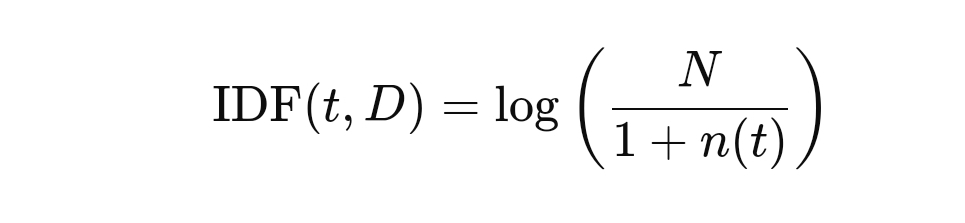
Burada, ( N ) doküman kümesindeki toplam doküman sayısını, ( n(t) ) ise kelimenin (( t )) kaç dokümanda geçtiğini ifade eder. Formüldeki “+1” terimi, sıfır bölme hatasını önlemek için eklenir. Sonuç olarak, bir kelime birçok dokümanda bulunuyorsa, IDF değeri düşük olacaktır. Nadir kelimeler ise daha yüksek IDF değerine sahip olacaktır.
TF-IDF Skoru:
TF-IDF skoru, bir kelimenin doküman içindeki önemini hesaplamak için TF ve IDF değerlerinin çarpımıyla elde edilir. Bu sayede, sadece dokümanda sık geçen değil, aynı zamanda diğer dokümanlara göre daha nadir olan kelimeler daha yüksek puan alır. Formülü şu şekildedir:
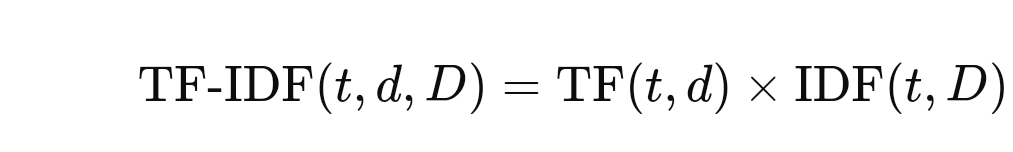
TF-IDF’in Uygulama Alanları
TF-IDF, çeşitli alanlarda yaygın olarak kullanılır:
- Arama Motorları:
Arama motorları, kullanıcının yaptığı sorguya en uygun sonuçları listelemek için TF-IDF kullanır. Bir kelimenin veya anahtar kelimenin bir web sayfasındaki önemini değerlendirerek, sorguyla en alakalı sonuçları sıralayabilir. - Metin Özetleme:
TF-IDF, otomatik metin özetleme sistemlerinde kullanılır. Özetleme algoritmaları, metindeki en önemli cümleleri belirlemek için TF-IDF skorlarını kullanarak hangi cümlelerin anahtar kelimeler içerdiğini tespit eder. - Spam Tespiti:
TF-IDF, spam e-postalarını tespit etmekte kullanılır. Spam maillerde sıkça geçen kelimeler düşük IDF değerlerine sahip olabilir, bu sayede bu tür e-postalar ayırt edilebilir. - Öneri Sistemleri:
Kullanıcılara öneriler sunan sistemlerde, içerik tabanlı filtreleme yapılırken dokümanlar arasındaki benzerliği ölçmek için TF-IDF kullanılabilir. Örneğin, bir kullanıcının beğendiği makaleye benzer içerikler, TF-IDF skorlarına göre belirlenir.
TF-IDF Avantajları ve Dezavantajları
Avantajları:
- Basit ve etkili bir yöntemdir. Hesaplanması ve uygulanması kolaydır.
- Kelimenin doküman içindeki ve doküman kümesindeki önemini anlamlı bir şekilde yansıtır.
- Metin sınıflandırma ve bilgi çıkarımı gibi çeşitli uygulamalarda başarıyla kullanılabilir.
Dezavantajları:
- TF-IDF sadece kelime frekansına dayanır ve kelimenin bağlamını göz önüne almaz. Bu nedenle kelimelerin anlam farklılıklarını yakalayamaz.
- Çok büyük veri setlerinde, hesaplaması daha karmaşık hale gelebilir.
- Sözcüklerin sırasını dikkate almadığı için, dilin yapısal özelliklerini gözden kaçırır.
TF-IDF Hesaplama Örneği
Bir metin kümesi üzerinde TF-IDF hesaplamanın nasıl yapıldığını basit bir örnekle açıklayalım. Örneğin elimizde şu üç doküman olsun:
- Doküman 1: “Kedi mırıldar”
- Doküman 2: “Kedi uyur”
- Doküman 3: “Köpek havlar”
Bu doküman kümesinde her kelimenin TF ve IDF değerlerini hesaplayalım.
TF Hesaplaması:
- “Kedi” kelimesi Doküman 1 ve 2’de geçiyor. Her bir dokümandaki TF değeri: ( \frac{1}{2} = 0.5 )
- “Köpek” kelimesi yalnızca Doküman 3’te geçiyor. TF değeri: ( \frac{1}{2} = 0.5 )
- “Havlar” ve “Mırıldar” kelimelerinin TF değerleri de benzer şekilde hesaplanır.
IDF Hesaplaması:
“Kedi” kelimesi iki dokümanda bulunduğu için IDF değeri şu şekilde hesaplanır:
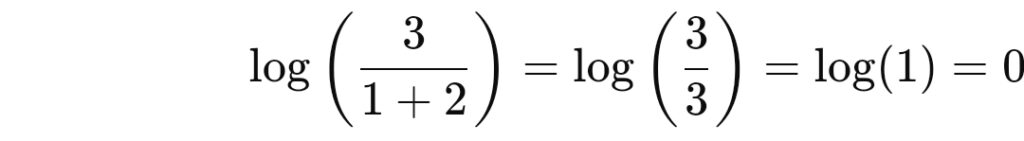
“Kedi” kelimesi yaygın olduğundan IDF değeri sıfırdır.
“Mırıldar” ve “Havlar” gibi kelimeler yalnızca bir dokümanda geçtiği için IDF değerleri daha yüksektir.
TF-IDF Hesaplaması:
TF ve IDF değerlerinin çarpımıyla TF-IDF skoru hesaplanır. “Kedi” kelimesi için TF-IDF skoru sıfır olacakken, nadir kelimeler daha yüksek değerlere sahip olacaktır.
Değerlendirme
TF-IDF, metin içerisindeki kelimelerin önemini ölçmek için kullanılan güçlü bir yöntemdir. Özellikle arama motorları, metin özetleme ve metin sınıflandırma gibi uygulamalarda yaygın olarak kullanılır. TF-IDF, basit ve etkili bir analiz sunarken, aynı zamanda kelimenin metin içerisindeki ve dokümanlar arası dağılımını dikkate alarak anlamlı sonuçlar üretir. Dezavantajlarına rağmen, metin madenciliği ve bilgi çıkarımı gibi süreçlerde hâlâ yaygın olarak tercih edilen yöntemlerden biridir.






